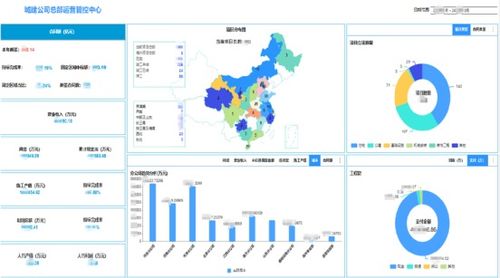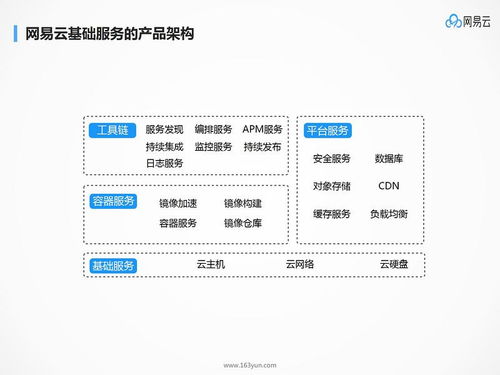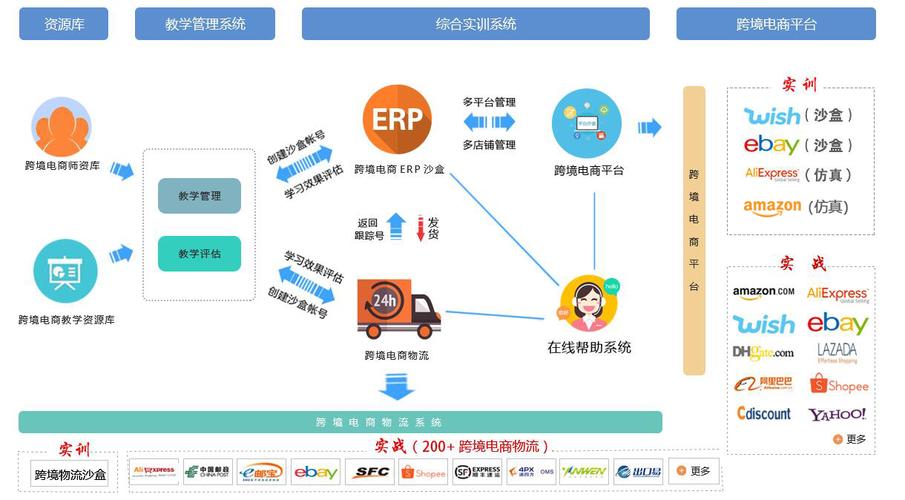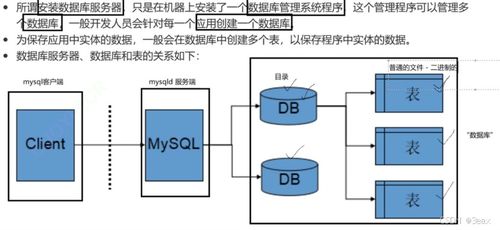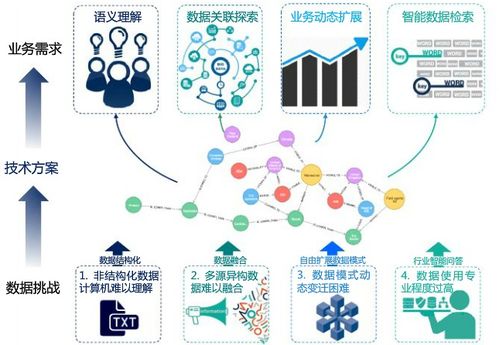
隨著大數(shù)據時代的到來,企業(yè)核心業(yè)務系統(tǒng)往往因處理海量數(shù)據而變得臃腫低效,影響整體響應速度和擴展性。因此,為業(yè)務“瘦身”已成為企業(yè)數(shù)字化轉型的必然選擇。本文將手把手帶你搭建一套高效的海量數(shù)據實時處理架構,結合數(shù)據處理和存儲支持服務,助力企業(yè)釋放數(shù)據潛力,提升業(yè)務敏捷性。
一、海量數(shù)據處理的挑戰(zhàn)與“瘦身”必要性
核心業(yè)務系統(tǒng)在數(shù)據量激增的背景下,常面臨以下痛點:
- 數(shù)據處理延遲高:傳統(tǒng)批處理方式無法滿足實時業(yè)務需求,導致決策滯后。
- 存儲成本飆升:非結構化數(shù)據(如日志、圖像)占用大量空間,且查詢效率低下。
- 系統(tǒng)擴展性差:單點架構難以應對突發(fā)流量,容易導致服務中斷。
“瘦身”并非單純削減功能,而是通過優(yōu)化數(shù)據處理流程,將非核心任務剝離,聚焦高價值業(yè)務邏輯。這不僅能降低系統(tǒng)負載,還能提升用戶體驗和運營效率。
二、搭建實時處理架構的關鍵步驟
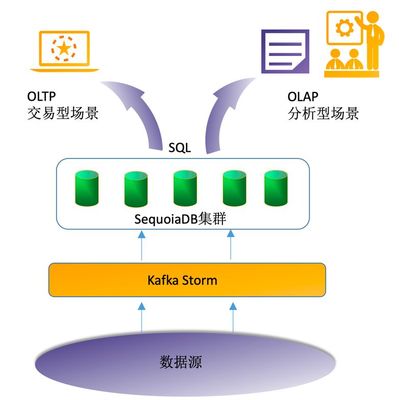
一個強大的海量數(shù)據實時處理架構通常包括數(shù)據采集、處理、存儲和分析四個環(huán)節(jié)。以下是逐步搭建指南:
- 數(shù)據采集層:采用分布式消息隊列(如Kafka或Pulsar)作為入口,支持高吞吐量的數(shù)據流入。例如,部署Kafka集群,配置多個主題(Topics)以分類處理業(yè)務數(shù)據,確保數(shù)據不丟失且低延遲。
- 數(shù)據處理層:引入流處理引擎(如Apache Flink或Spark Streaming)進行實時計算。通過編寫處理邏輯(如過濾、聚合、轉換),實現(xiàn)對數(shù)據的即時分析。例如,使用Flink處理用戶行為流,實時識別異常模式并觸發(fā)告警。
- 數(shù)據存儲層:選擇混合存儲方案,結合NoSQL數(shù)據庫(如Cassandra或HBase)用于高速讀寫,以及數(shù)據湖(如AWS S3或HDFS)存儲原始數(shù)據。這支持靈活查詢和歷史回溯,同時控制成本。
- 數(shù)據服務層:通過API網關和微服務架構,暴露處理后的數(shù)據給業(yè)務系統(tǒng)。例如,構建RESTful API,讓前端應用實時獲取分析結果。
整個架構需輔以監(jiān)控工具(如Prometheus)和自動化運維,確保高可用和可擴展性。
三、數(shù)據處理和存儲支持服務的集成
為簡化搭建過程,企業(yè)可借助云端數(shù)據處理服務(如AWS Kinesis或Google Dataflow)和存儲服務(如云對象存儲或分布式數(shù)據庫)。這些服務提供托管解決方案,減少運維負擔:
- 數(shù)據處理服務:自動擴展計算資源,處理峰值流量;例如,使用Kinesis Data Streams實時處理點擊流數(shù)據。
- 存儲支持服務:提供分層存儲選項,冷數(shù)據歸檔至低成本存儲,熱數(shù)據存于內存數(shù)據庫(如Redis)以加速訪問。
通過集成這些服務,企業(yè)只需關注業(yè)務邏輯,快速實現(xiàn)“瘦身”目標。
四、實踐案例與最佳實踐
以電商行業(yè)為例:某平臺通過搭建上述架構,將訂單處理從批處理改為實時流處理,延遲從小時級降至秒級,同時利用云存儲服務降低了30%的存儲成本。關鍵最佳實踐包括:
- 逐步遷移:先從小規(guī)模數(shù)據流開始測試,再擴展至核心業(yè)務。
- 數(shù)據治理:實施數(shù)據清洗和標準化,確保質量。
- 安全合規(guī):加密數(shù)據傳輸和存儲,遵循GDPR等法規(guī)。
五、總結與展望
核心業(yè)務“瘦身”不僅是技術優(yōu)化,更是戰(zhàn)略轉型。通過手把手搭建海量數(shù)據實時處理架構,并整合數(shù)據處理和存儲支持服務,企業(yè)能構建敏捷、高效的數(shù)據驅動體系。隨著AI和邊緣計算的融合,實時處理將更智能,助力企業(yè)在競爭中脫穎而出。開始行動吧,讓你的業(yè)務輕裝上陣,駕馭數(shù)據洪流!